
学习 | 备战计算机二级 Python
Day 1
1 变量命名要求与类型
1.1 Python3.5及以上版本的保留字总数是(35个)
- False await else import pass
- None break except in raise
- True class finally is return
- and continue for lambda try
- as def from nonlocal while
- assert del global not with
- async elif if or yield
1.2 Python 的变量命名需要注意的是
- 由数字、字母、下划线组成
- 不能以数字开头、变量名不能包含特殊字符,如@、#、$
- 不能使用Python内置关键字
- 严格区分大小写
| OK 的变量 | NO 的变量 |
|---|---|
| Ture_i、_1ok、变量 | and、!ok、233a、@ss |
2 Python 的数据类型
type(var) # 可以使用函数来获取变量的数据类型
# 整数:<class'int'>
# 浮点数:<classfloat'> !只有十进制表现形式
# 复数:<class'complex'>
# 字符串:<class'str'>
# 布尔类型:<class'bool'>
2.1 数值型 - 整数型
整数型可以是:-100、13 这样的数,当然也可也是进制数,以下进制表示也是整数型。
| 进制数 | 引导符号 | 补充 | 例子 |
|---|---|---|---|
| 十进制 | 无 | 默认情况 | 110、-110 |
| 二进制 | 0b 或 0B | 由 0 和 1 组成 | 0b1010、0B1010 |
| 八进制 | 0o 或 0O | 由 0 到 7 组成 | 0o010、0O1010 |
| 十六进制 | 0x 或 0X | 由 0 到 9 、a 到 f 组成 | 0x01AFFB |
2.1.1 进制转换 —— 按权展开式
二进制 -> 十进制
$1010=1 \times 2^3+0 \times 2^2+1 \times 2^1+0 \times 2^0=8+0+2+0=10$
八进制 -> 十进制
$167=1 \times 8^2+6 \times 8^1+7 \times 8^0=64+48+7=119$
十六进制 -> 十进制
$24 B=2 \times 16^2+4 \times 16^1+11 \times 16^0=512+64+11=587$
2.3 数值型 - 浮点类型
普通浮点数: 1.23 3.14
科学计数法浮点数: 1.01e4 -1.2E5 (计算方法见下)
$1.01e4=1.01 \times 10^4=10100.0$
2.4 数值型 - 复数类型 (实际上用的不多)
复数 $z = a+bj$ ,其中 $a$ 是实数部分,简称实部, $b$ 是虚数部分,简称虚部(高中学过啦)。虚数部分通过后缀“”或“j”来表示。
$j=\sqrt{-1}$,j为虚数单位
注意:当b为1时,1不能省略,即 $1j$。
例:$11.3 + 4j$ 、$-5 + 2j$ 、 $10+5j$
对于复数 z ,可以使用 z.real 和 z.imag 分别获取它的实部和虚部。 以下为例子
a = 12 + 5j
print(a.real) # 获取变量 a 的实数部分
print(a.imag) # 获取变量 a 的虚数部分
# !返回的均是浮点类型x = 10
y = -1 + 2j
print(x + y) # 结果输出 (9+2j)2.5 数据类型 - 字符串
字符串并不陌生,和 PHP 、JAVA 一样使用"或者'括起来。以下为例子
但 Python 可以用三个上面的符号进行直接换行,下面的strC为例子
strA = "Hello World"
strB = 'hello word'
strC = """各位同人们:
大家好!
我是XXX,接下来...
"""注意:使用直接换行时不要将第一个"""后又回车,不然就变成了多行注释了!
2.6 数据类型 - 布尔类型
通常用于逻辑判断 True & False 无需多言!
3 运算符 & 连接符
算术运算符共九种,下表为九种运算符的描述与实例。
3.1 算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| // | 取整除 - 返回商的整数部分(向下取整) | >>> 9//2 4>>> -9//2 -5 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| + | x 本身 | +x |
| - | x 的负值,即x * (-1) | -x |
注意:使用整型 + 字符串你得线转换,见下方例子。
prize = 9.15
string = "衬衫的价格是:"
end = '$'
print(string + end + str(prize))
# 输出为:衬衫的价格为:$9.15
x = "hello!"
print(x * 2)
# 输出为:hello!hello!3.2 赋值运算符、增强赋值操作符
| 运算符 | 实例 | 描述 |
|---|---|---|
| = | c = a + b 将 a + b 的运算结果赋值为 c | 简单的赋值运算符 |
| += | c += a 等效于 c = c + a | 加法赋值运算符 |
| -= | c -= a 等效于 c = c - a | 减法赋值运算符 |
| *= | c = a 等效于 c = c a | 乘法赋值运算符 |
| /= | c /= a 等效于 c = c / a | 除法赋值运算符 |
| %= | c %= a 等效于 c = c % a | 取模赋值运算符 |
| **= | c = a 等效于 c = c a | 幂赋值运算符 |
| //= | c //= a 等效于 c = c // a | 取整除赋值运算符 |
特别的玩法:
a = 3
b = 5
a, b =b, a # 将 a 的值和 b 互换
s1 = s2 = s3 = 123 # 同时赋值多个变量
print(s1, s2, s3)3.3 关系运算符
以下假设变量a为10,变量b为20:
| 运算符 | 实例 | 描述 |
|---|---|---|
| == | (a == b) 返回 False。 | 等于 - 比较对象是否相等 |
| != | (a != b) 返回 True。 | 不等于 - 比较两个对象是否不相等 |
| <> | (a <> b) 返回 True。这个运算符类似 != 。 | 不等于 - 比较两个对象是否不相等。Python3 已废弃。 |
| > | (a > b) 返回 False。 | 大于 - 返回x是否大于y |
| < | (a < b) 返回 True。 | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量 True 和 False 等价。 |
| >= | (a >= b) 返回 False。 | 大于等于 - 返回x是否大于等于y。 |
| <= | (a <= b) 返回 True。 | 小于等于 - 返回x是否小于等于y。 |
3.4 逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 实例 | 描述 |
|---|---|---|---|
| and | x and y | (a and b) 返回 20。 | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 |
| or | x or y | (a or b) 返回 10。 | 布尔"或" - 如果 x 是非 0,它返回 x 的计算值,否则它返回 y 的计算值。 |
| not | not x | not(a and b) 返回 False | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 |
3.5位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13,二进制格式如下:
a = 0011 1100
b = 0000 1101
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| 竖 | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a 竖 b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:将二进制表示中的每一位取反,0 变为 1,1 变为 0。~x 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011 (以补码形式表示),在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
print "1 - c 的值为:", c
c = a | b; # 61 = 0011 1101
print "2 - c 的值为:", c
c = a ^ b; # 49 = 0011 0001
print "3 - c 的值为:", c
c = ~a; # -61 = 1100 0011
print "4 - c 的值为:", c
c = a << 2; # 240 = 1111 0000
print "5 - c 的值为:", c
c = a >> 2; # 15 = 0000 1111
print "6 - c 的值为:", c
# 1 - c 的值为: 12
# 2 - c 的值为: 61
# 3 - c 的值为: 49
# 4 - c 的值为: -61
# 5 - c 的值为: 240
# 6 - c 的值为: 15注意:他不同于与 PHP 的“并且”运算 Python 需要使用 and
4 常用的函数
4.1 input() 函数
input 函数可以接收键盘输入的内容,数据类型为 String 字符串。以下为例子。
#输入三角形的三边长
a,b,c = (input("请输入三角形三边的长:").split())
a= int(a)
b= int(b)
c= int(c)
#计算三角形的半周长p
p=(a+b+c)/2
#计算三角形的面积s
s=(p*(p-a)*(p-b)*(p-c))**0.5
#输出三角形的面积
print("三角形面积为:",format(s,'.2f'))输出结果为:
请输入三角形三边的长:3 4 5
三角形面积为: 6.00
4.2 if-else 条件语句(二分支结构)
if 判断条件:
执行语句……
else:
执行语句……由于 python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现,如果判断需要多个条件需同时判断时,可以使用 or (或),表示两个条件有一个成立时判断条件成功;使用 and (与)时,表示只有两个条件同时成立的情况下,判断条件才成功。
### if 语句多个条件
num = 9
if num >= 0 and num <= 10: # 判断值是否在0~10之间
print 'hello'
# 输出结果: hello
num = 10
if num < 0 or num > 10: # 判断值是否在小于0或大于10
print 'hello'
else:
print 'undefine'
# 输出结果: undefine
num = 8
# 判断值是否在0~5或者10~15之间
if (num >= 0 and num <= 5) or (num >= 10 and num <= 15):
print 'hello'
else:
print 'undefine'
# 输出结果: undefine注意:当 if 有多个条件时可使用括号来区分判断的先后顺序,括号中的判断优先执行,此外 and 和 or 的优先级低于>(大于)、<(小于)等判断符号,即大于和小于在没有括号的情况下会比与或要优先判断。
4.3 循环语句的使用
循环语句主要与两个,一个是 for 遍历循环,一个是 while 无限循环!
4.3.1 while 循环
while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务。其基本形式为:
while 判断条件:
执行语句
prize = 100
while prize > 60:
print(str(prize) + "还是太贵了!再便宜一点~")
prize -= 10
print("行!就" + str(prize) + "吧!")bye!"注意:当然还有一种特别的情况。以下为例子
sum = 0
i = 1
while i < 100:
sum = sum + i
i = i + 1
else:
# 当 while 达到条件循环结束以后还会执行一次 else 相当于还有一次没有达到条件
print(sum)4.3.1.1 循环控制
在循环中我们可以使用 continue 来结束当前本次循环并且 continue 后面的代码不会继续执行,直接执行下一次循环!
break 来跳过循环,退出循环!以下为例子
# 输出 1 - 100 的所有偶数
i = 0
while i < 100:
i += 1
if i % 2 == 0:
print(i)
# 输出 1 - 100 的所有奇数
i = 0
while i < 100:
i += 1
if i % 2 == 0:
continue
else:
print(i)
# 输出 1 - 100 的前 3 个偶数
count = 0
i = 0
while i < 100:
if count == 3:
break
i += 1
if i % 2 == 0:
count += 1
print(i)4.3.2 for() 遍历循环
可迭代对象:如字符串、列表、元组、字典等可以用来遍历循环的数据。
for<循环变量> in <可迭代对象>:
<循环体>s1 = "abcdefg"
for i in s1:
print(i)
# 他就会一行一行输出 abcdefg4.4 print() 打印函数
print() 函数没有上面多介绍的,值的注意的是打印后还可以跟数值。例如以下例子
print(123,end = "元") # end 的默认值为 \n
# 输出为:123元,并且不会换行了!5 程序的异常处理
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
注意:这里说的异常不是语法错误!
一般情况下,在Python无法正常处理程序时就会发生一个异常。
异常是Python对象,表示一个错误。当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
捕捉异常可以使用 try/except 语句。
try/except 语句用来检测try语句块中的错误,从而让except 语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在 try 里捕获它。以下为例子。
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生# 它打开一个文件,在该文件中的内容写入内容,且并未发生异常
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()Day 2
6 函数的基础
对内隐藏细节,对外暴露接口。 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。函数能提高应用的模块性,和代码的重复利用率。
6.1 定义一个函数
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
def functionname( parameters ): "函数_文档字符串" function_suite return [expression]
特别的:函数不可以为空,但是我们可以用 pass 语句对清占位置。以下为例子
def sample(n_samples):
pass # 但在Python3.x的时候pass可以写或不写6.2 函数调用
定义一个函数只给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行。
如下实例调用了printme()函数:
def printme( str ):
"打印任何传入的字符串"
print str
return
# 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")下面我将用一个例子来进行学习:
形式参数:简称“形参”,函数定义(声明)时使用的参数。
实际参数:简称“实参”,函数被调用时实际传入的参数。
# 两位数加法运算
def plusNumber(a,b): # a 和 b 是形参
return(a + b)
returnValue = plusNumber(5,6) # 5 和 6 是实参
print(returnValue)当然,使用元组也可也实现以下功能:
def fun(a,b)
return b,a
n,m = fun(3,4)
print(n) # 输出为46.3 函数参数与返回值
一个函数可以是 无参数、无返回值;无参数,有返回值;
# 输出1-100之间的和
# 无参数、无返回值
def fun1():
sum = 0
i=1
whilei<=100:
sum +=i
i+=1
print(sum)
# 计算1-100之间的和,并返回
# 无参数,有返回值
def fun2():
sum = 0
i = 1
while i<=100:
sum +=i
i+=1
return sum
# 实现传入一个成绩,判断该成绩是否及格,并输出“及格”或“不及格
def fun3(s):
if s >= 60:
print("及格”)
else:
print("不及格”)
fun3(60)
# 实现传入一个成绩,判断该成绩是否及格,及格返回 True ,否则返回 False
def fun4(s):
if s >= 60
return True
else:
return False一个函数也可也设定他的传参默认值(可选参数),当没选中使保证程序可用!
[Warnning!] 可选参数必须放到 非可选参数后面,不然会报错
def fun(a, b = 5):
return a + b
print(fun(1)) #结果输出为 6
def fun(a, b = 5):
return a + b
print(fun(1,1)) #结果输出为 26.4 函数变量的作用域
在一个 Python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误
n = 2 # n 为全局变量
def fun(a,b):
global n # 声明在本作用域中使用全局变量 n
n = a * b
print(n)
fun(5,6) # 输出为 307 常见的字符串操作
7.1 字符串操作符号
常见的字符串操作符又 3 种:
| 运算符 | 举例 | 描述 |
|---|---|---|
| + | x + y | 字符串 x 与字符串 y 连接 |
| * | x * y | 复制 y 次字符串 x |
| in | x in y | 如果 x 是 Y 的子串,返回 True,否则返回 False |
使用 in 就可以实现判断某个字符是否在字符串里面出现过。以下为例子
s1 = "How are you?"
print("are" in s1) # 输出为 True7.2 字符串的索引与切片
索引 用来表示字符串中字符的所在位置,基于位置,可以快速找到其对应的字符,如果一个字符串中有n个字符,那么索引l的取值范围是 0~n~1
<字符串或字符串变量>[索引]
s = "How are you?"
print(s[0]) #结果输出为 H (空格也算)切片 可以获取字符串指定索引区间的字符!
值得注意的是:开始索引和结束索引是左闭右开区间。例子如下。
<字符串或字符串变量>[开始索引:结束索引:步长(默认1)]
s = "How are you?"
print(s[1:6]) # 结果输出为 ow ar(不包含第6个字符e)
print(s[1:]) # 从第一个位置到最后一个字符
print(s[:8]) # 从第 0 个字符取到第八个字符,不包括第八个字符
print(s[:]) # 不用多说了!举一反三 ~
print(s[0:11:2]) # 加入步长,没格2个字符取一个(不包含第二字符)
# 输出为 Hwaeyu
print(s[::-1]) # 步长为 -1 可以逆向排列
# 输出为?uoy era woH7.3 字符串中常用函数
| 函数 | 描述 |
|---|---|
| len(x) | 返回字符串x的长度,也可返回其他组合数据类型的元素个数 |
| str(x) | 返回任意类型 x 所对应的字符串形式 |
| chr(x) | 返回Unicode编码 x 对应的单个字符 |
| ord(x) | 返回单字符 x 表示的Unicode 编码 |
| hex(x) | 返回整数 x 对应十六进制数的小写形式字符串 |
| oct(x) | 返回整数 x 对应八进制数的小写形式字符串 |
7.4 字符串常用处理方法
这个 str 类的方法
| 方法 | 描述 |
|---|---|
| str.lower0 | 返回字符串str的副本,全部字符小写 |
| str.upper() | 返回字符串str的副本,全部字符大写 |
| str.spli(sp=None) | 返回一个列表,由str根据sep被分割的部分构成,省略sep默认以空格分隔 |
| str.count(sub) | 返回sub子串出现的次数 |
| str.replace(old, new) | 返回字符串str的副本,所有old子串被替换为new |
| str.center(width,fiilchar) | 字符串居中函数,fillchar参数可选(默认空格)width(小于本身直接返回) |
| str.strip() | 从字符串str中去掉在其左侧和右侧chars中列出的字符 |
| str.join(iter) | 将iter变量的每一个元素后增加一个str字符串 |
| capitalize() | 将字符串首字母变大写 |
| index(sub, begin, end) | 返回 sub 在当前字符串第一次出现的位置,没有找到就报错 |
| find(sub, begin, end) | 返回 sub 在当前字符串第一次出现的位置,没有找到返回-1 |
7.5 字符串格式化处理
<模板字符串>.format(<参数列表>)
模板字符串是一个由字符串和槽组成的字符串,用来控制字符串和变量的显示效果。槽 用 {} 表示,与 format() 中的参数列表对应。以下为例子。
s1 = """欢迎您!{}:
新的一天也要元气满满哦 ~ """
print(s1.format("admin"))
s1 = """欢迎您!{0}:
新的一天也要{1}哦 ~ """
print(s1.format("往来无白丁","不折不挠"))
# 输出:欢迎您!往来无白丁:\n新的一天也要不折不挠哦 ~ 以下用法例子来自菜鸟教程:
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的还可以对其格式化处理(处理的时候就不可以赋值了):
| : | <填充> | <对齐> | <宽度> | <,> | <精度> | <类型> |
|---|---|---|---|---|---|---|
| 引导符号 | 用于填充单个字符 | < 左对齐<br/>> 右对齐<br/>^ 上对齐 | 槽的设定输出宽度 | 数字的千位分隔符适用于整数和浮点数 | 浮点数小数部分的精度或字符串的最大输出长度 | 整数类型b,c,,d,o,x,X浮点类型e,E,f,% |
# b:整数二进制形式
# c:输出整数对应的Unicode字符
# d:整数十进制形式
# o:整数八进制形式
# X:整数大写十六进制形式
# x:整数小写十六进制形式
# f:四舍五入保留x位小数
s = "二级考试"
print("{:*^25}".format(s))
# 输出为:**********二级考试***********
s = "全国计算机二级考试"
print("{:.5}".format(s))
# 输出为:全国计算机
print("{1}:{0:.6f}".format(3.1415926,"pi"))
# 输出为:pi:3.141593Day 3
8 组合数据类型
组合数据类型主要分为集合类型、序列类型、映射类型
8.1 集合类型 - set
Python i语言中的集合类型与数学中的集概念一致。集合用来存储无序并且不重复的数据。集合中元素的类型只能是不可变数据类型,如:整数、浮点数、字符串、元组等。相比较而言,列表、字典、和集合类型本身都是可变数据类型。
例:S = {123, 3.14,"HelloWorld", True}
集合也有他的操作符,和数学集合一样
| 操作符 | 数学名称 | 描述 | |
|---|---|---|---|
| s - t | 差集 | 返回一个新集合,包括在集合s中但不在集合t中的元素 | |
| s & t | 交集 | 返回一个新集合,包括同时在集合s和t的元素 | |
| s ^ t | 补集 | 返回一个新集合,包括集合s和t中非共同元素 | |
| s \ | t | 并集 | 返回一个新集合,包括集合s和t中所有元素 |
集合类型常用操作方法
| 函数或方法 | 描述 |
|---|---|
| s.add(x) | 如果数据项x不在集合s中,将x添加到s |
| s. remove (x) | 如果x在集合s中,移除该元素,不在则产生 KeyError 异常 |
| s.clear() | 移除s中所有的元素 |
| len(s) | 返回集合s的元素个数 |
| x id s | 如果x是s的元素,返回True,否则返回False |
| x not in s | 如果x不是s的元素,返回True,否则返回False |
Q:创建一个空集合?
set1 = set()
# 而不是:set1 = {} // 这样是一个字典类型8.2 序列类型
序列类型用来存储有序并且可以重复的数据,分别为以下两种类型类型:列表(list) 元组(tuple)
8.2.1 列表类型 - list
索引 用来表示列表中元素的所在位置基于位置,可以快速找到其对应的列表元素如果一个列表中有n个元素,那么索引的取值范围是0~n-1 <列表或列表变量>[索引]
切片 可以获取列表指定索引区间的元素
<列表或列表变量>[开始索引:结束索引]
<列表或列表变量>[开始索引:结束索引:步长]
ls = [123,"123",3.14,"abc"]
# 打印为:[123, '123', 3.14, 'abc']
print(ls[::-1]) # 倒序排列列表类型常用操作符与函数
| 函数或方法 | 描述 |
|---|---|
| x in s | 如果x是s的元素,返回True,否则返回False |
| x not in s | 如果x不是s的元素,返回True,否则返回False |
| len(s) | 返回列表s的元素个数 |
| min (s) | 返回列表s中的最小元素 (同一数据类型) |
| max (s) | 返回列表s中的最大元素(同一数据类型) |
列表类型常用操作方法
| 函数或方法 | 描述 |
|---|---|
| ls.append (x) | 在列表ls末尾处理添加一个新元素x |
| ls.insert(i,x) | 在列表ls第i位增加元素x |
| ls.clear() | 清空列表ls中所有元素 |
| ls.pop (i) | 将列表ls中第i个元素删除,默认最后一个 |
| ls.remove (x) | 将列表中出现的第一个元素x删除(已知元素内容) |
| ls.reverse() | 将列表ls中的元素反转 |
| ls.index(x) | 列表ls中第一次出现元素x的位置 白 |
| ls.count(x) | 列表ls中出现x的总次数 |
| ls.copy() | 返回一个新列表,复制ls中所有元素 |
Q:创建一个空列表?
ls1 = list()
ls1 = []
# 这样是一个字典类型Q:如何复制一个新列表?
ls1 = [123,321,1234567]
ls2 = ls1
ls2[1] = 3.14
print(ls1,ls2)
# 输出为:[123, 3.14, 1234567] [123, 3.14, 1234567]很明显,ls1输出出现了问题,按理来说应该是 [123,321.1234567]
可结果是 [123, 3.14, 1234567] 这是为什么呢?
这里我们就要提到计算机底层方面的 堆栈 与 静态存储区 ,我用一张图来表示:

所以如何正确复制一个新列表?
ls1 = [123,321,1234567]
ls2 = ls1.copy()
ls2[1] = 3.14
print(ls1,ls2)
# 输出为:[123, 321, 1234567] [123, 3.14, 1234567]8.2.2 元组类型
元组一旦定义就不能修改元组类型使用()来表示,例:t = (123,3.14,123,"abc")
以下是常用操作符与函数
| 函数或方法 | 描述 |
|---|---|
| xins | 如果x是s的元素,返回True,否则返回False |
| x not in s | 如果x不是s的元素,返回True,否则返回 False |
| len(s) | 返回元组s的元素个数 |
| min (s) | 返回元组s中的最小元素 |
| max(s) | 返回元组s中的最大元素 |
| ls.index(x) | 元组1s中第一次出现元素x的位置 |
| 1s.count(x) | 元组ls中出现x的总次数 |
8.3 字典类型
字典类型数据主要以“键值对”的形式存储,类似汉语字典的目录形式。具体定义格式如下:{<键1>:<值1>,<键2>:<值2>,....,<键n>:<值n>}
以下为常用的操作函数:
| 函数或方法 | 描述 |
|---|---|
| len(d) | 返回字典d的元素个数 |
| min(d) | 返回字典d中键的最小值 |
| max(d) | 返回字典d中键的最大值 |
字典类型常用操作方法
| 函数或方法 | 描述 |
|---|---|
| d. keys() | 返回所有的键信息 |
| d.values() | 返回所有的值信息 |
| d.items() | 返回所有的键值对 |
| d. get (key, default) | 键存在则返回相应值,否则返回默认值de fault |
| d. pop (key, default) | 键存在则删除相应键值对,并返回相应值,否则返回默认值default |
| d.popitem() | 随机从字典中取出一个键值对,以元组(key, value)形式返回,同时 将该键值对从字典中删除。 |
| d.clear() | 清空字典d中所有键值对 |
配合 for 循环进行操作
d = {"student":[{"name":"唐僧"},{"name":"孙悟空"},{"name":"猪八戒"},{"name":"沙悟净"}]}
for i in d["student"]:
print(i["name"])
print(i)
# 输出为
"""
唐僧
{'name': '唐僧'}
孙悟空
{'name': '孙悟空'}
猪八戒
{'name': '猪八戒'}
沙悟净
{'name': '沙悟净'}
"""
# 当然我们也可也这样:
d2 = {"20240101":"张伟","20240102":"李华","20240103":"王强"}
for i in d2.values():
print(i)
# 输出姓名列 张伟...
for i in d2.items():
print(i)
# 输出元组列 ("20240101","张伟")...
print(i[1])
# 输出姓名列 张伟...
for k,v in d2:
print(v)
# 输出为姓名列 张伟...9 文件的处理
操作流:打开文件(open())->读/写->关闭文件(close())
- 文本文件
一般由单一特定编码的字符组成,如Unicode编码,内容容易统一展示和阅读,由于文本文件存在编码,可以看作是存储在磁盘上的长字符串,如一个txt格式的文本文件。
- 二进制文件
直接由0和1组成,没有统一的字符编码,文件内部数据的组织格式与文件用途有关。如png格式的图片文件、mkv格式的视频文件。
区别: 是否有统一的字符编码
9.1 相对路径与绝对路径
总体来说和 PHP 的差不多,相对路径以程序路径作为参照物。
相对路径:path = "a/test.txt"
绝对路径:path = "D:/testFile/a/test.txt"
值得一提的是 Python 中的转义字符
| 符号 | 含义 |
|---|---|
| \n | 换行 |
| \t | tab |
| \\ | \ |
9.2 打开文件
使用 open() 函数打开文件 <变量名> = open(<文件路径及文件名>,<打开模式>)
| 打开模式 | 描述 |
|---|---|
| 'r' | 只读模式,如果文件不存在,返回异常FileNotFoundError,默认值 |
| 'w' | 覆盖写模式,文件不存在则创建,存在则完全覆盖原文件 |
| 'x' | 创建写模式,文件不存在则创建,存在则返回异常 FileExistsError |
| 'a' | 追加写模式,文件不存在则创建,存在则在原文件最后追加内容 |
| 'b' | 二进制文件模式 |
| 't' | 文本文件模式,默认值 |
| '+' | 与r/w/x/a一同使用,在原功能基础上增加同时读写功能 |
文件打开的常用组合
- 以文本方式只读打开一个文件,读入后不能对文件进行修改:r
- 以文本方式可读写地打开一个文件,可以读入并修改文件:r+
- 以文本方式打开一个空文件,准备写入一批内容,并保存为新文件:w
- 以文本方式打开一个空文件或已有文件,追加形式写入一批内容,更新原文件:a+
- 以二进制方式只读打开一个文件,读入后不能对文件进行修改:rb
9.2 文件读取
| 方法 | 描述 |
|---|---|
| f.read(size) | 从文件中读入整个文件内容。参数可选,如果给出,读入前size长度的字符 串或字节流 |
| f. readline(size) | 从文件中读入一行内容。参数可选,如果给出,读入该行前size长度的字符 串或字节流 |
| f.readlines (hint) | 从文件中读入所有行,以每行为元素形成一个列表。参数可选,如果给出, 读入hint行 |
| f.seek(offset) | 改变当前文件操作指针的位置,offset的值:0为文件开头;1为从当前位 置开始;2为文件结尾 |
| f.tell(offset) | 获取当前文件操作指针的位置 |
这里我们需要关注也有个易错点
path = "a/test.txt"
f = open(path, "r", encoding="UTF-8")
s = f.read()
print(s)
ls = f.readlines()
print(ls)
f.close()
# 结果输出 大家好,欢迎!\n里面请!\n []为什么我们读取文件后再输出列表就输出为空列表呢?这里就不得不提到 “指针” 了。指针是什么?就类似于光标,我已一次读取的时候指针以及在文本末尾了,第二次读取就是从文本末尾读取,当然读取不到东西,这里我们就需要用到 seek() 方法了!
path = "a/test.txt"
f = open(path, "r", encoding="UTF-8")
s = f.read()
print(s)
f.seek(0)
ls = f.readlines()
print(ls)
f.close()9.3 文件写入
| 方法 | 描述 |
|---|---|
| f.write(s) | 向文件写入一个字符串或字节流 |
| f.writelines(lines) | 将一个元素为字符串的列表整体写入文件 |
例如:
f = ...
f.writelines("["123123", "321321"]")
# 存储就是一行一个9.4 数据的读取与存储
9.4.1 一维数据
一维数据就如他名字所说的,一般用一些特定符号进行分割数据,例如(“ ”、“;”、“\n”)等等。储存形式为 Csv 不如 json 方便 下面为一个一维数据例子:
Android手机.csv:小米;华为;OPPO;VIVO
考试中一般配合 splite() 函数方法食用!
易错题:
列表ls = [1,2,3,4,5,6,[7,8,9]],以下选项中描述正确的是( A )
A.ls 可能是一维列表 B.ls 可能是二维列表
C.ls 可能是多维列表 D.ls 可能是高维列表
9.4.2 二维数组
这里需要多加练习了, 摘录一个将 CSV 转换成列表的例子
File:student.scv
姓名, 性别, 年龄
李华,男,18
王强,女,19
翠翠,女,20f = open("students.csv", "r")
student = []
for line in f:
line = 1ine.strip("\n") #去除换行符
temp = 1ine.split(",")
student.append(temp)
f.close()
print(student)
# 输出:[[“姓名”,“性别”,“年龄”],[“李华”,“男”,“18”],...]10 Python 模块/库的使用
10.1 内置函数
| 函数名 | 描述 |
|---|---|
| abs (x) | x 的绝对值。如果 x 是复数,返回复数的模 |
| divmod(a,b) | 返回 a 和 b 的商及余数。如 divmod(10,3) 结果是一个 (3,1) |
| pow (x,y) | 返回 x 的 y 次幂。如 pow(2, pow(2,2)) 的结果是 16 |
| round (n) | 四舍五入方式计算 n。如 round(10.6) 的结果是 11 |
| all (x) | 组合类型变量x中所有元素都为真时返回 True ,否则返回 False ;若 x 为空,返回 True. |
| any (x) | 组合类型变量x中任一元素都为真时返回 True ,否则返回 False ;若 x 为空,返回 False. |
| reversed(r) | 返回组合类型r的逆序形式。 |
| sorted(x) | 对组合数据类型 x 进行排序,默认从小到大。 |
| sum (x) | 对组合数据类型 x 计算求和结果。 |
| eval(s) | 计算字符串 s 作为 Python 表达式的值。 |
| exec(s) | 计算字符串 s 作为 Python 语句的值。 |
| range(a,b,s) | 从 a 到 b(不包含 b )以 s 为步长产生一个序列。 |
10.2 模块的引用
import
- import <模块名> as <别名>
from ... import ...
- from <模块名> import <对象、函数>
# import 引用
import test1 as t
test1.fuc()
t.fuc()
# 如果不想要test1 或者 t
# 可以用form ... import ... 引用( * 所有引用)
from test1 import fuc, add
fuc()
add()
plus() # 这样就不行,因为 import 没提及!10.3 标准库的使用
10.3.1 turtle —— 海龟绘图
使用 海龟绘图 可以编写重复执行简单动作的程序画出精细复杂的形状。在 Python 中,海龟绘图提供了一个实体“海龟”形象(带有画笔的小机器动物),假定它在地板上平铺的纸张上画线。
10.3.1-1 窗体函数
turtle.setup(width,height,startx,starty)
width:窗口宽度
height:窗口高度
startx:窗口与屏幕左侧距离(单位象素)
starty:窗口与屏幕顶部距离(单位象素)
10.3.1-2 画笔运动命令
| 命令 | 说明 |
|---|---|
| turtle.forward(distance) | 向当前画笔方向移动distance像素长度 |
| turtle.backward(distance) | 向当前画笔相反方向移动distance像素长度 |
| turtlr.penup() / pu() / up() | 提起画笔;不绘制图形,用于另起一个地方绘制 |
| turtle.pendown() / pd() / down() | 放下画笔;移动时绘制图形,缺省时也为绘制 |
| turtle.circle(R,L) | 画圆,半径 R 为正(负),表示圆心在画笔的左边(右边)画圆,弧长 L ; L位置也可以写 steps=6 (内切六边形) |
| dot(r) | 绘制一个指定直径和颜色的圆点 |
| turtle.left(degree) | 逆时针移动degree° |
| turtle.right(degree) | 顺时针移动degree° |
| turtle.goto(x,y) | 将画笔移动到坐标为x,y的位置 |
| setx( ) | 将当前x轴移动到指定位置 |
| sety( ) | 将当前y轴移动到指定位置 |
| setheading(angle) / sethead() | 设置当前朝向为angle角度 |
| home() | 设置当前画笔位置为原点,朝向东。 |
| speed() | 设置画笔的绘制的速度,参数为 0~10 之间 |
10.3.1-3 画笔控制命令
| 命令 | 说明 |
|---|---|
| turtle.pensize() | 笔的粗细(默认为1) |
| turtle.color(color1, color2) | 同时设置 pencolor = color1, fillcolor = color2 |
| turtle.pencolor((r,g,b)) | 画笔的颜色,可用英文单词颜色亦可 RGB 颜色 |
| turtle.fillcolor(colorstring) | 绘制图形的填充颜色 |
| turtle.begin_fill() | 准备开始填充图形 |
| turtle.end_fill() | 填充完成 |
| turtle.filling() | 返回当前是否在填充状态 |
| turtle.hideturtle() | 隐藏画笔的 turtle 形状 |
| turtle.showturtle() | 显示画笔的 turtle 形状 |
10.3.1-4 全局控制命令
| 命令 | 说明 |
|---|---|
| turtle.clear() | 清空turtle窗口,但是turtle的位置和状态不会改变 |
| turtle.reset() | 清空窗口,重置turtle状态为起始状态 |
| turtle.undo() | 撤销上一个turtle动作 |
| turtle.screensize() | 设置背景色、窗口大小 |
| turtle.isvisible() | 返回当前turtle是否可见 |
| turtle.hideturtle() | 隐藏笔 |
| turtle.showturtle() | 现实笔 |
| stamp() | 复制当前图形 |
| turtle.write(s [,font=("font-name",font_size,"font_type")]) | 写文本,s为文本内容,font是字体的参数,分别为字体名称,大小和类型;font为可选项,font参数也是可选项 |
Example 1.
画一个八边形
import turtle as t
t.setup(600,600,20,20)
for i in range(8):
t.forward(50)
t.right(45)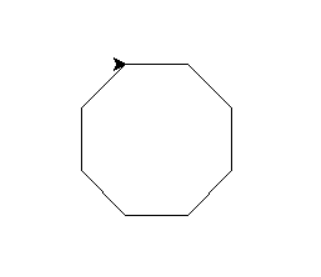
10.3.2 random —— 伪随机数
Python 的随机算法采用 梅森旋转算法
| 函数名 | 描述 |
|---|---|
| seed(a = None) | 初始化随机数种子,默认值为当前系统时间 |
| random() | 生成一个 [0.0,1.0) 之间的随机小数 |
| randint(a,b) | 生成一个 [a,b] 之间的整数 |
| getrandbits (k) | 生成一个k比特长度的随机整数 |
| randrange(start, stop[,step]) | 生成一个 [start, stop) 之间以 step 为步长的随机整数 |
| uniform(a, b) | 生成一个 [a,b] 之间的随机小数 |
| choice (seq) | 从序列类型(例如列表)中随机返回一个元素 |
| shuffle(seq) | 将序列类型中元素随机排列,返回打乱后的序列 |
| sample (pop, k) | 从 pop 中随机选取 k 个元素,以列表类型返回 |
10.4 第三方库的使用
10.4.1 第三方库的安装
第三方库的安装主要是三种方式,pip工具安装、自定义安装、文件安装(扩展名.whl)
10.4.1-1 pip 工具的使用
pip <命令> <选项>
安装:install 库名
卸载:uninstall 库名
下载:download 库名
查看当前第三方库列表:list
查看某个第三方信息:show

10.4.2 jieba 库
jieba(“结巴”)是Python中一个重要的第三方中文分词函数库,能够将一段中文文本分割成中文词语的序列,jieba库需要通过 pip 指令安装。
10.4.2-1 常用函数
| 函数名 | 描述 |
|---|---|
| jieba.lcut(s) | 精确模式,返回一个列表类型 |
| jieba.lcut(s, cut_all=True) | 全模式,返回一个列表类型 |
| jieba.lcut for_search(s) | 搜索引擎模式,返回一个列表类型 |
| jieba.add_word(w) | 向分词词典中增加新词 w |
import jieba
test_content = '迅雷不及掩耳盗铃儿响叮当仁不让世界充满爱之势'
cut_res = jieba.lcut(test_content)
print(list(cut_res))
cut_res = jieba.lcut(test_content, cut_all=True)
print(list(cut_res))
# ['迅雷不及', '掩耳盗铃', '儿响', '叮', '当仁不让', '世界', '充满', '爱之势']
# ['迅雷', '迅雷不及', '迅雷不及掩耳', '不及', '掩耳', '掩耳盗铃', '儿', '响叮当', '叮当', '当仁不让', '不让', '世界', '充满', '爱', '之', '势']
Python 二级考试只需要了解这么多,更多详细了解:jieba,为中文分词而生的Python库 —— 知乎
10.4.3 其他第三方库
| 库名 | 描述 |
|---|---|
| requests | 简洁且简单处理HTTP请求 |
| scrapy | Web获取框架,一个半成品爬虫 |
| numpy | 科学计算库 |
| scipy | 在 numpy 基础上增加了很多库函数 |
| pandas | 数据处理、数据分析 |
| pdfminer | 读取pdf数据 |
| openpyxl | 处理Excel表格 |
| python-docx | 处理 word 文档 |
| beautifulsoup4 | 解析和处理HTML、XML |
| matplotlib | 二维图绘制 |
| TVTK | 三维可视化 |
| mayavVi | 更方便的三维可视化 |
| PyQt5 | 用户图形界面开发 |
| wxPython | 用户图形界面开发 |
| Pycrk | 用户图形界面开发 |
| scikit-learn | 机器学习 |
| TensorFlow | 人工智能 |
| Theano | 深度学习 |
| Django | Web框架 |
| Pyramid | Web框架 |
| Flask | Web框架 |
| Pygame | 多媒体制作 |
| Panda3D | 3D引擎 |
| cocos2d | 2D引擎 |
| PIL、Pillow | 图像处理 |
| SymPy | 数学计算 |
| NLTK | 自然语言处理 |
| WeRoBot | 微信机器人框架 |
| MyQR | 二维码 |
Day 4
第四天 Python 二级所考的知识点已全部学完,下面是刷题部分!






@Pudding
禁止捣乱
φ( ̄∇ ̄o) 一起来学C